They see me role-in…
I had an interesting question come up recently that I’m ashamed to admit, I hadn’t really given a huge amount of thought to before:
if a very permissive role is attached to an EC2 instance, how do you go about preventing unprivileged users from using the granted permissions?
If you’ve spent any time using AWS, you know that you can attach IAM roles directly to some services, like EC2. This has at least a couple of pretty awesome advantages:
- It allows you to grant access to applications and services for specific resources within AWS. If an application running on EC2 needs to store backups to an S3 bucket, attach an appropriate role and it just works.
- All credentials are temporary. No access keys or anything to share out which could leak and expose sensitive data or allow unintended access.
How does it work?
Continuing with the EC2 service as an example, there is a special non-routable IP that’s configured within the instance (169.254.169.254). You can even browse this using the curl command:
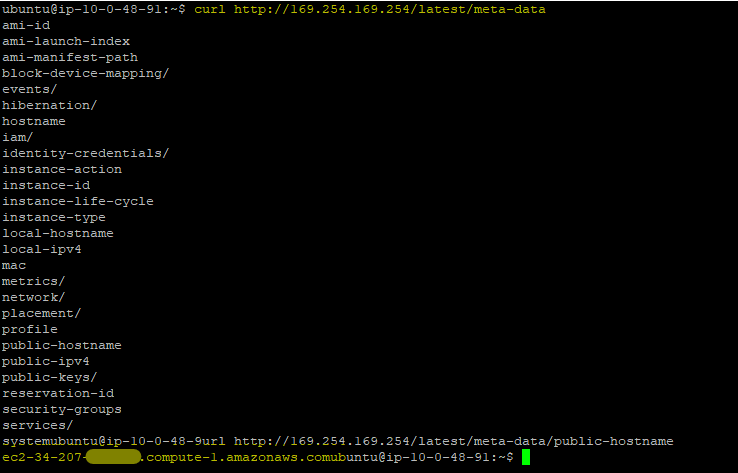
Whenever the AWS CLI command or the SDK needs access, it makes an HTTP call to this IP address, requesting credentials. The metadata service then calls the AWS Security Token Service (STS) which generates a set of short-term, temporary credentials (an Access Key, Secret Key, and Session Token), and passes them back for use by the application.
So, what’s one to do?
Back to the question: how do you prevent an unprivileged user from using the attached role? Short answer: you can’t, really. There isn’t any way to pass the user’s credentials from within the OS to AWS via the metadata. When an IAM role is attached to an Amazon EC2 instance, any user logged into that instance can assume the role and inherit its permissions. This somewhat comes down to the separation between security “OF” the Cloud versus “IN” the Cloud. You’re responsible for making sure you know what you’re doing once you start poking holes in your security. If you’re letting a user into a system, you’d better be sure about them. So, what’s one to do?
One approach would be to configure the attached role as just a “gatekeeper” role. This would implement an extra step to prevent bad actors from just by default having too much access. As applications or users need to elevate their permissions, they would then use the attached role to call the administrative one.
So, what does this look like?
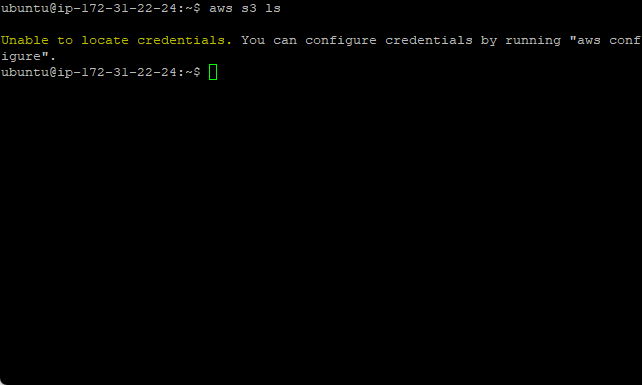
Without an IAM role associated, no permissions available:
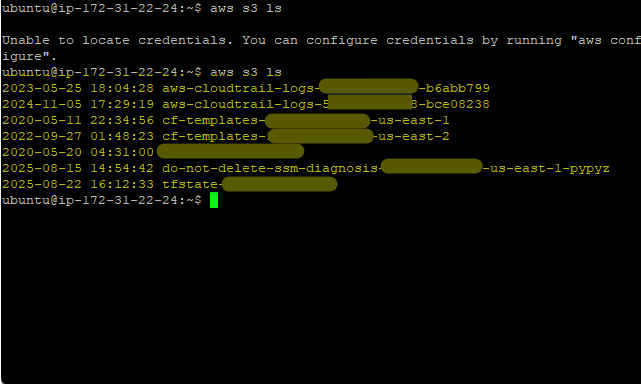
With administrative role attached, S3 bucket list operation is successful:
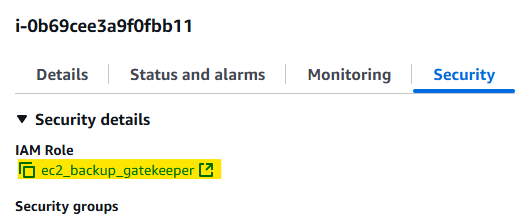
Ok, now let’s change things up a bit. First off, we attach the gatekeeper role:
IAM Role Turst Policy{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": {
"Service": "ec2.amazonaws.com"
},
"Action": "sts:AssumeRole"
}
]
}
IAM Policy – assume_s3_bucket_full_access{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "VisualEditor0",
"Effect": "Allow",
"Action": "sts:AssumeRole",
"Resource": "arn:aws:iam::<ACCOUNT #>:role/s3_test_full_access"
}
]
}
IAM Role – s3_test_full_access
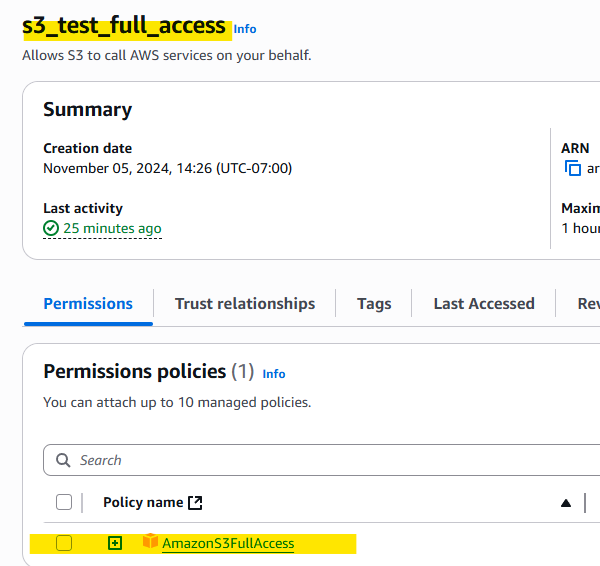
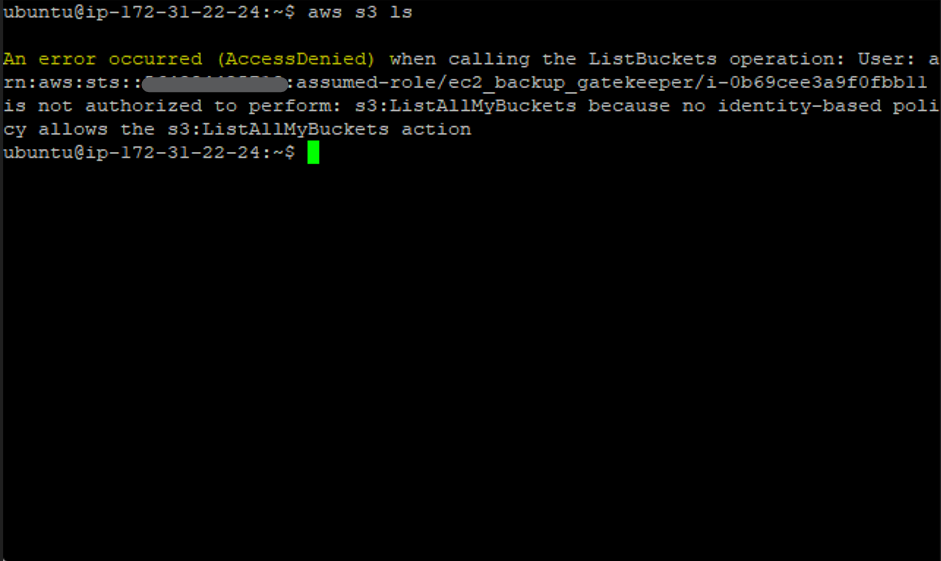
With gatekeeper role attached:
Now, after we assume the alternate role, we are able to successfully use the elevated permissions and view the S3 buckets:
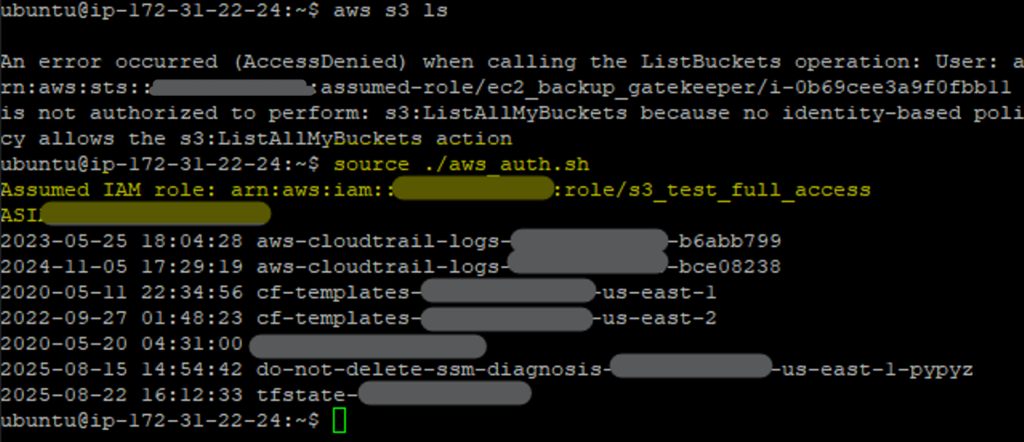
Note I’m using the following script to perform the aws assume-role command
#!/bin/bash
# Get the current Linux username
LINUX_USER=$(whoami)
# Map Linux users to their specific IAM role ARNs
declare -A ROLE_MAPPING
ROLE_MAPPING[ubuntu]="arn:aws:iam::<ACCOUNT#>:role/s3_test_full_access"
# Check if the current user has a mapped role
if [ -n "${ROLE_MAPPING[$LINUX_USER]}" ]; then
ROLE_ARN=${ROLE_MAPPING[$LINUX_USER]}
# Assume the role and get temporary credentials
CREDS=$(aws sts assume-role --role-arn "$ROLE_ARN" --role-session-name "${LINU X_USER}-session" --query 'Credentials' --output 'json')
# Export the credentials as environment variables
if [ -n "$CREDS" ]; then
export AWS_ACCESS_KEY_ID=$(echo "$CREDS" | jq -r '.AccessKeyId')
export AWS_SECRET_ACCESS_KEY=$(echo "$CREDS" | jq -r '.SecretAccessKey')
export AWS_SESSION_TOKEN=$(echo "$CREDS" | jq -r '.SessionToken')
echo "Assumed IAM role: $ROLE_ARN"
else
echo "Failed to assume IAM role."
unset AWS_ACCESS_KEY_ID
unset AWS_SECRET_ACCESS_KEY
unset AWS_SESSION_TOKEN
fi
else
# Unset credentials for users without a mapped role
unset AWS_ACCESS_KEY_ID
unset AWS_SECRET_ACCESS_KEY
unset AWS_SESSION_TOKEN
fi
# Print the AWS Access Key - Troubleshooting only
echo $AWS_ACCESS_KEY_ID
# Perform an AWS S3 ls to test - Troubleshooting only aws s3 ls
Warning!
You’ve probably already guessed this by now, but if the administrative role is known, anybody with access to the system can still assume it. You would then need to take extra precautions around who is allowed to run specific applications. For instance, you could then lock down permissions to the aws command to only allow a specific group to execute it. That would probably still leave some concerns around general users if they could initiate an API call to assume the role, but that would come down to really being stringent about only allowing specific users access to the system.
So, anyway, this was a fun challenge. Feel free to reach out and let me know how this could be done differently or, preferably, better!


